
应用介绍
系统使用快速入门
通过阅读本文,您可以初步了解该软件系统的结构、使用流程以及一些有效的设置。
第一节 系统安装
将安装光盘放入计算机的光盘驱动器中,直接运行程序setup.exe,根据安装向导的提示,就可以完成安装操作。
第二节 选择扫描仪
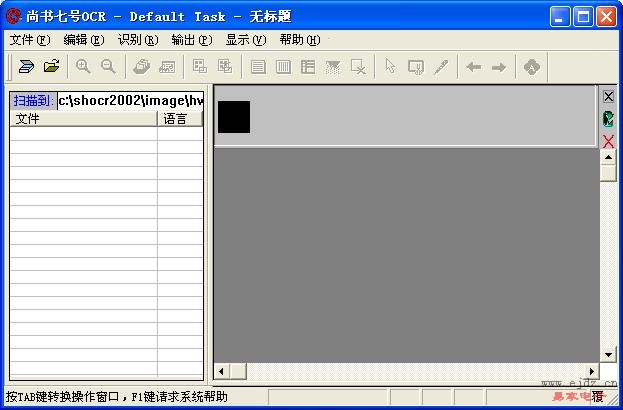
第一次使用扫描仪或者更换扫描仪时,都需要安装和设置扫描仪驱动程序。请先按照扫描仪使用手册上的步骤正确安装扫描仪驱动程序,然后打开本系统主程序,在应用程序界面内,单击“文件”菜单中的“选择扫描仪”命令,选择相应的扫描仪,如图:
第三节 系统设置
单击“文件”菜单中的“系统配置”命令,进入系统设置界面,设置扫描任务的语言及彩色图片的保存格式。如下图:
支持的扫描任务语言有:中文简体、简繁混合、纯英文等。
如果选中“灰度彩色图像总存为JPG”,那么扫描时,系统会自动将灰度、彩色图像文件保存成JPG格式;如不选中该项,图像文件格式是根据用户在“扫描到”窗口中的设定(图像名后缀)来保存的。此设置只对灰度、彩色图像有效。
如果选中“识别”页中的“自动倾斜校正”,在自动版面分析时,系统会自动校正倾斜的图像文件。如下图:
第四节 操作流程简介
一、获取图像:
有两种方式获取图像,扫描图像或打开计算机中已经存在的图像文件。本系统支持24位彩色、256级灰度和二值黑白图像。
扫描图像之前应设置好保存扫描图像文件的路径、图像文件名、图像文件名后缀。设置图像路径,可以直接在 窗口中键入路径名,或单击 按钮,在浏览路径窗口中选定路径。
图像名的命名规则为: 若干位字母前缀+3位数字,3位数字的范围从000到999,每扫描一幅图像后系统会自动在数字尾数加1,如图像名前缀取“hw”,图像名数字尾数取“003”,图像名后缀取tif,则当前图像名为hw003.tif,下一幅图像名自动改为hw004.tif;如果当前图像名尾数达到最大值,如hw999.tif,则下一幅图像名自动改回为hw000.tif,所以相同路径下相同文件名前缀的文件数最多为1000幅。
如果扫描过程中弹出“此文件已经存在,是否替换该文件?”提示框,说明该路径下已经存在同名的旧图像文件,如果旧图像文件不再需要,择选择“是”,以新扫描的图像替换旧图像;如果还需要旧图像文件,则选择“否”,并在“另存到”窗口中重新设定路径或图像文件名。不同批次的扫描图像最好分别保存于不同的路径之下,或者在相同路径下而选取不同的图像名前缀,以防止相同路径下相同文件名前缀的文件数超过1000幅。
图像文件名后缀只能取bmp,tif,jpg 三种图像格式,一般情况下,黑白二值图像保存为tif格式,灰度彩色图像保存为jpg格式将占用较少的硬盘空间。例如,C:\hwocr\image\hw003.tif是一个完整合法的图像文件名。
单击工具栏上的按钮或单击“文件”菜单中的“扫描”命令,通过扫描仪开始批量扫描文件;单击工具栏上的按钮或单击“文件”菜单中的“打开图像”命令,打开计算机中已经扫描好的图像文件(注意:图像文件所在路径必须是可写的)。
二、图像处理:
为提高识别率,对图像进行图像反白,自动倾斜校正,调整边框,去噪音(如麻点、下划线等),表格画线等处理。
三、版面分析:
单击工具栏中的按钮,或单击“识别”菜单中的“版面分析”命令,自动对图像的版面布局、内容进行分析理解,切分图像页,判别图像框的版面属性(横栏、竖栏、表格、图像),并以不同颜色的线框标识图像框属性。对分析错误的版面可以手动调整,方法为,先以鼠标选中需要调整的版面块,再调整版面块的边框改变大小,或单击工具栏上的属性按钮(横栏、竖栏、表格、图像)改变该版面块属性。
四、识别图像:
单击按钮或单击“识别”菜单中的“开始识别”命令,按照版面属性(横栏、竖栏、表格、图像),自动对图像文件管理器选择的图像进行批量识别。
五、校对:
通过对比识别结果文本和原图像,以发现识别错误的文字。用户可按Ctrl+Tab、Shift+Tab组合健直接查找系统用醒目的颜色标出的可信度不高的文字,进行校对。
六、版面还原:
单击“输出”菜单中的“到指定格式文件”命令,将识别并修改好的文本输出、还原成可供计算机阅读和查询检索的RTF、HTML、XLS、TXT 格式的电子文档。
七、删除不再需要的数据文件:
系统在识别处理过程中生成一些数据文件,这些文件和相关的图像文件放在同一文件夹之下,这些文件以对应的图像文件名字命名而分别加上不同的后缀,包括 *.bki,*.pst,*.tmp。例如对于图像文件hw003.tif,对应生成的数据文件有hw003.tif.bki(不一定存在该文件),hw003.tif.pst,hw003.tif.tmp。当这些图像的识别结果不再需要时,用户可以使用Windows资源管理器删除这些文件。
第五节 使用技巧
1.如果用户从光盘上复制图像及数据进行进行处理,务必先将这些文件的只读属性去掉。
2.处理纯英文文档时,识别语言选项设定为“简体”、“简繁”、“英文”都可以,但设定为“英文”识别效果最好;当处理含有繁体字的文档时,语言选项应设定为“简繁”。
3.如果表格结构因为断线而识别错误,可以先用工具按钮中的画笔在图像上弥补断线再重新版面分析。
4.识别效果不佳的主要原因
(1) 扫描设置不当,扫描图像时的扫描分辨率(Resolution)一般应设为300dpi,如果文档字体较小则需要将扫描分辨率设定为更高值如400dpi或600dpi。缩放比例(Scaling)设为100%,亮度阀值(Threshold,Brightness)需根据纸张和印刷的质量调节,避免扫描图像过黑或过淡 。
(2) 如自动版面分析有错误,这时请用户用鼠标自己划分出正确的版面块;版面块的版式设置错误,如将横版的设置为竖版,竖版的设置为横版等,这时请用户自行将块的版式修改正确。
(3) 原稿印刷质量太差,笔画断裂严重、油墨太浓、字与字之间粘连严重等也可能使识别率显著降低。
(4) 识别语言选项选择不当,应根据原稿正确选择“简体”、“简繁”或“英文”。
5.建议系统使用IE5.0以上版本,否则可能影响正确浏览联机帮助文档。
如果您在使用本系统时还有什么问题,请查阅本软件系统的联机帮助。
图片1
《尚书七号扫描仪文字识别系统.rar》资讯
暂无数据
《尚书七号扫描仪文字识别系统.rar》教程/攻略
暂无数据
评论
举报
发表
暂无评论,期待你的妙语连珠
详细信息
- 厂商
暂无
- 官网
暂无
- 是否内购
无
- 语言
简体中文
- 年龄段
全年龄对象
- 当前版本
暂无
- 大小
0KB
- 授权方式
免费
- 网络
否
- 权限
查看权限



 渝公网安备50010702505138号
渝公网安备50010702505138号